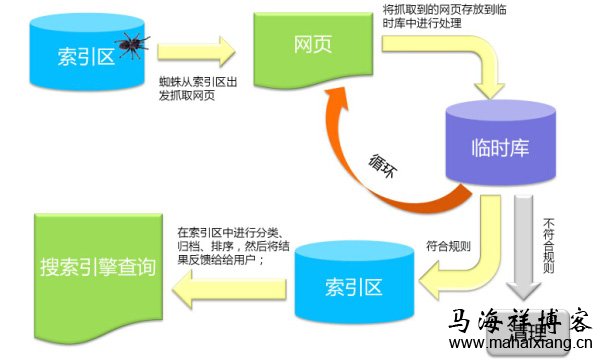
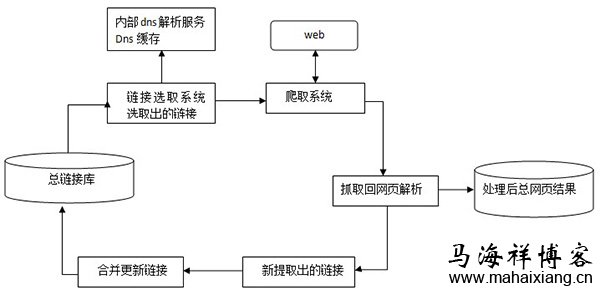
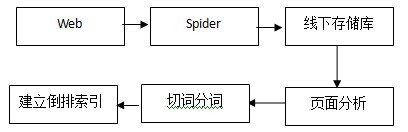
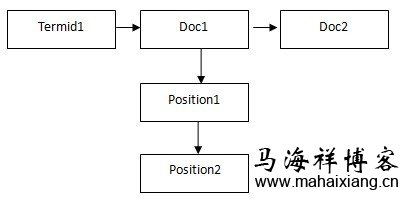
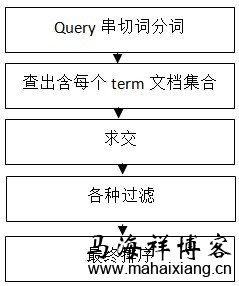
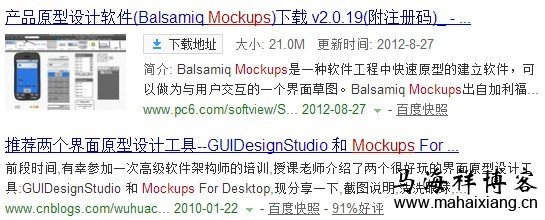
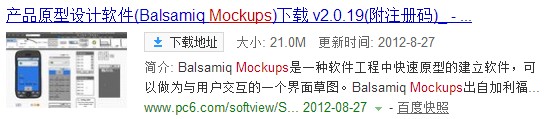
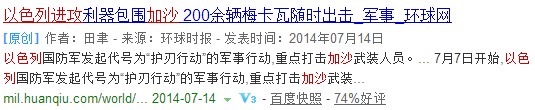
10 0x123abc 号 0x13445d 线 0x234d 地铁 0x145cf 故障 0x354df
0x123abc 1 2 3 4 7 9….. 0x13445d 2 5 8 9 10 11…… …… ……